
Abstract
Introduction: High-quality primary care can reduce avoidable emergency department visits and emergency hospitalizations. The availability of electronic medical record (EMR) data and capacities for data storage and processing have created opportunities for predictive analytics. This systematic review examines studies which predict emergency department visits, hospitalizations, and mortality using EMR data from primary care.
Methods: Six databases (Ovid MEDLINE, PubMed, Embase, EBM Reviews (Cochrane Database of Systematic Reviews, Database of Abstracts of Reviews of Effects, Cochrane Central Register of Controlled Trials, Cochrane Methodology Register, Health Technology Assessment, NHS Economic Evaluation Database), Scopus, CINAHL) were searched to identify primary peer-reviewed studies in English from inception to February 5, 2020. The search was initially conducted on January 18, 2019, and updated on February 5, 2020.
Results: A total of 9456 citations were double-reviewed, and 31 studies met the inclusion criteria. The predictive ability measured by C-statistics (ROC) of the best performing models from each study ranged from 0.57 to 0.95. Less than half of the included studies used artificial intelligence methods and only 7 (23%) were externally validated. Age, medical diagnoses, sex, medication use, and prior health service use were the most common predictor variables. Few studies discussed or examined the clinical utility of models.
Conclusions: This review helps address critical gaps in the literature regarding the potential of primary care EMR data. Despite further work required to address bias and improve the quality and reporting of prediction models, the use of primary care EMR data for predictive analytics holds promise.
- Artificial Intelligence
- Electronic Health Records
- Emergency Room Visits
- Hospitalization
- Primary Health Care
- Systematic Review
Introduction
Primary health care is the foundation of health systems. High-quality primary care reduces the need for more expensive acute health services and is associated with improved population health outcomes.1,2 Strengthening primary health care has a direct impact on system performance and resiliency during public health emergencies.3,4 Rising health care costs5⇓–7, increases in health services utilization,8 and the limits to the capacities of acute care services9⇓–11, drive the need for more proactive and preventative interventions in primary health care.12 Past research has identified that some hospitalizations and a significant proportion of emergency department visits are preventable and amenable to primary care intervention.13
Primary health care offers a unique and effective setting to intervene to reduce acute health service use, the need for costly interventions, and to reduce premature mortality.14 Greater engagement by patients with primary care has been associated with decreased risk of emergency hospitalization,15 and emergency department visits,16 and early contact after hospital discharge has been found to reduce readmissions by as much as 50%.17,18 Primary health care plays a significant role in patient coordination of care and the redistribution of health system burden and resource use.19
We now have an opportunity to implement data-driven approaches to support clinical decision making and to reduce acute care service use through proactive care within primary care settings.9,20 Over the past decade, the adoption of electronic medical records (EMR) within primary health care has gained momentum. According to the Commonwealth Fund International Health Policy survey, the number of family physicians who report using EMRs in practice has grown steadily in recent years.21 This is particularly true in the United States and Canada, where rates of EMR use have doubled over 10 years (46% to 92% and 37% to 86%, respectively). As of 2019, an average of 93% of primary care physicians report using EMRs in practice internationally.22,23 The longitudinal nature and population-based health approach of primary care means that primary care EMRs offer a rich source of data that holds the potential for use in predictive analytics.24,25 Furthermore, the growth in primary care EMR data availability, coupled with advances in data storage and processing capabilities, have paved the way for new technologies, such as artificial intelligence, to improve medical care.26,27
Expanding on prior systematic reviews that have explored the use of prediction models for identifying hospitalizations, ED visits, or mortality, there are notable gaps in the literature regarding the use of primary care EMR data. Although prior reviews have made significant contributions in predicting these outcomes, they predominantly feature studies reliant on hospital data, or administrative health databases such as physician billing claims databases, rather than solely focusing on EMR data.28⇓⇓–31 Moreover, even within reviews focused on EMR data, substantial gaps remain, particularly emphasizing the use of primary care EMR data.32⇓–34 Furthermore, many of these studies have found variable performance and modest discriminative ability. Given the longitudinal nature and richness of primary care EMR data, using such data in prediction models has the potential to significantly enhance model performance.
Despite the need and opportunity for data-driven, proactive primary care interventions, little is known about the prevalence, rigor, and clinical suitability of prediction models that process primary care data to predict of emergency department visits, hospitalizations, and mortality. Currently, no previous review has thoroughly examined the use of primary care EMR data in these outcomes. This review aims to address these intersecting gaps, providing a nuanced understanding of prediction models which use EMR data within primary care settings. Considering the gaps in literature, this systematic review aims to address the following primary research question: what are the published studies on the use of primary health care EMR data to predict emergency department visits, hospitalizations, and mortality? Our objectives were threefold: 1) to examine candidate predictors which contribute to high-performance prediction models; 2) describe model performance; and 3) identify and report on existing model’s contributions to clinical care and decision making.
Methods
A systematic review was conducted to identify all relevant studies on the use of primary care electronic medical record data to predict emergency department visits, hospitalizations, and mortality. The study protocol was registered with the International Prospective Register of Systematic Reviews (PROSPERO, registration: CRD42020136625), and results are presented in accordance with Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines.
Databases and Search Strategy
Six electronic databases (Ovid MEDLINE, PubMed, Embase, EBM Reviews (Cochrane Database of Systematic Reviews, Database of Abstracts of Reviews of Effects, Cochrane Central Register of Controlled Trials, Cochrane Methodology Register, Health Technology Assessment, NHS Economic Evaluation Database), Scopus, CINAHL) were used to search the peer-reviewed literature from inception. The search was initially conducted on January 18, 2019, and updated on February 5, 2020. The Journal of Medical Internet Research (JMIR), Journal of Medical Informatics (JMI) and the Journal of the American Medical Informatics Association (JAMIA), as well as the reference lists of selected studies, were hand-searched for additional citations. In consultation with an information specialist, specific search strategies were developed for each database (sample search strategy can be found in Appendix A).
Eligibility Criteria
Studies were included if they were: (1) primary quantitative studies; (2) evaluated the performance of a new statistical or mathematical model, algorithm, or other forms of model, or external validation of an existing model; (3) predicted a single endpoint outcome of either emergency department visits, hospitalization, or mortality; (4) used electronic medical record data from outpatient primary health care. We included studies related to people of any age. Exclusion criteria include data originating from article records or sources outside of primary care, such as emergency departments, census data, or surveys. Commentaries, editorials, thesis dissertations, and reviews were also excluded. Included studies were restricted to those published in English; however, no restrictions were made to the search by country.
Study Identification
After removing duplications, all relevant citations were imported into DistillerSR (Evidence Partners, Ottawa, ON) to support citation management, screening, and conflict resolution. A number of study volunteers were engaged and trained to assist with reviewing citations. Title and abstracts were screened by 2 independent reviewers to assess for study inclusion. The full texts that were considered suitable for inclusion were reviewed by 2 independent members of the study team to ensure eligibility and then proceeded to data extraction. Any disagreements between reviewers were addressed by the study team and resolved with the principal investigator (ADP) as the arbitrator.
Data Extraction
A standardized data extraction form was developed in accordance with guidelines established by the Checklist for Critical Appraisal and Data Extraction for Systematic Reviews of Prediction Modeling Studies (CHARMS)35 and was prepiloted by study team members (Appendix B). Relevant data were extracted in duplicate (R.J., T.C.), and disagreements were resolved through study team meetings. The extracted data included information on the study setting and participants, data sources, outcomes, predictor variables, sample size, missing data, model development, and results. If information was not available from an article it was noted during data extraction.
Data Synthesis and Analysis
Meta-analysis was considered to examine pooled outcomes of model performance, however, heterogeneity in terms of study settings, populations, data, and outcomes precluded this approach, and it was deemed not feasible for this study. Therefore, results were examined using narrative synthesis. To bring together key features of model development and performance, results were presented according to the prediction outcome of interest when appropriate and organized as follows: study setting and population, predictor variables considered and included in final models, prediction outcomes, and model development and performance. Discrimination, the model’s ability to accurately distinguish between individuals who experience the event of interest and those who do not, was used to assess predictive performance and reported using concordance (c) statistics, or area under the curve (AUC) with 95% confidence intervals when available.36 A c statistic of 0.5 indicates no discriminative ability, akin to random chance. Optimizing predictive accuracy and discriminative ability is crucial for real-world application, instilling confidence in the model's ability to inform clinical decision making. The performance of predictive models carries significant clinical implications for patients, care clinicians, and health system resources.36 Instead of c-statistics or AUC measures, sensitivity, specificity, negative predictive value, and positive predictive value were reported when necessary.
Quality Appraisal and Risk of Bias Assessment
The quality and risk of bias (ROB) of individual studies were assessed using the Prediction Model Risk of Bias Assessment Tool (PROBAST).37 Each study was independently evaluated (R.J., T.C.) using the provided signaling questions and subsequently 7afforded a score of “high,” “low,” or “unclear” risk of bias in accordance with PROBAST scoring guidelines.
Results
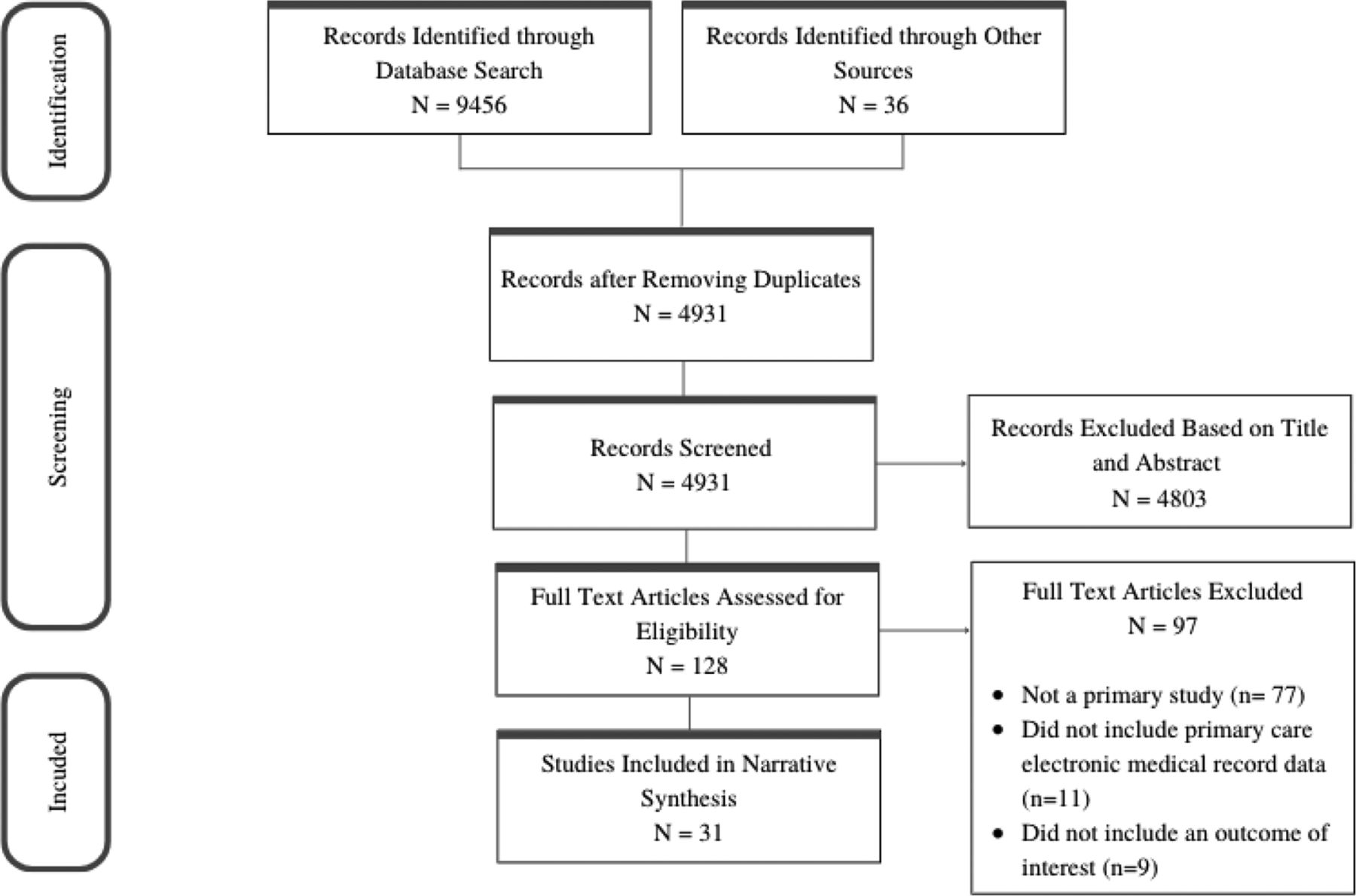
The electronic databases search strategy retrieved 9456 studies. Of these, 4967 studies were screened by title and abstract, resulting in 164 being selected for full-text review. The final review included 31 studies which met inclusion criteria (Figure 1). Overall, of the analyzed risk prediction models, 16 (44.4%) aimed to identify individuals at risk of hospitalization, 7 (19.4%) focused on the risk of ED visits, and 13 (36.1%) on the risk of mortality. Although a subset of these models focused on specific patient populations, such as those with chronic kidney disease or HIV-positive patients admitted to hospital, the majority were developed in an adult general practice or community hospital population.

PRISMA flow diagram. Abbreviation: PRISMA, Preferred Reporting Items for Systematic Reviews and Meta-Analyses.
Study Characteristics
Within the 31 included studies, most (n = 18, 58.1%) reported on models developed using data from the United States.38⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓–55 The remainder of the studies were from the United Kingdom (n = 7, 22.6%)56⇓⇓⇓⇓⇓–62, Canada,63 Ireland,64 and Australia65 (n = 1, 3.2% each), and Israel (n = 2, 6.5%)66,67, whereas 1 study utilized data from health centers across multiple countries.68 Among the 31 included studies, 5 studies utilized unique models to address more than 1 outcome, creating a total of 36 prediction models. Sixteen models (44.4%) focused on the prediction of hospitalization; of these, 5 focused on the risk of hospital readmission.44,46,47,66,67 Thirteen models (36.1%) were developed to predict mortality, including 3 which specifically examined the outcome of patient suicide mortality,49,51 and 1 risk of opioid overdose.50 Furthermore, 7 models (19.4%) assessed the risk of emergency department visits.38⇓⇓⇓–42,63,65 A majority of studies (n = 30, 96.7%) implemented a retrospective cohort design, 2 of which coupled this with prospective cohort validation, and 1 study exclusively utilized a prospective cohort design.28
Of the total studies included in this review, 23 (74.2%) utilized electronic medical record data in combination with other large sources of data, including health care administrative data (n = 7) death repositories (n = 7) and population demographics data (such as census data) (n = 8). In addition to primary care medical record data, 6 (19.4%) studies included in this review utilized data linkages to capture hospital and health service use, but more commonly, this data were often stored in tandem with primary care data (n = 25, 80.6%). Of the 25 studies which developed models using a single source of EMR data, more than half (n = 13) used data housed within institutional or national health care repositories. The total sample size in each study ranged from 607 patients to >4.6 million patients. A complete overview of study characteristics is presented in Table 1.
Characteristics of Studies and Model Development
Model Characteristics
Several of the studies evaluated the predictive performance of models across a number of outcomes (n = 8), populations (n = 4), prediction windows (n = 4), or across a number of prediction methods (n = 3) and variable subsets (n = 8). The most frequently used statistical analysis method was logistic regression, which was used in 17 studies (54.8%). Of the total, 13 studies (41.9%) developed predictive models using artificial intelligence methods. Most validated models internally (n = 20, 64.5%) or used a combination of both internal and external validation (n = 7, 22.6%). Most commonly, methods of internal validation used a split sample approach (n = 16, 51.6%) or the more comprehensive technique of cross-validation (n = 6, 19.4%), which assesses model performance across multiple subsets of data.
Four studies28,39,45,56 (12.9%) discussed the clinical implementation of prediction models or developed models for real-time utilization in clinical practice and to inform clinical decision making. More specifically, Morawski, Dvorkis, & Monsen (2020) developed a model that utilizes a data warehouse, which couples clinical EMR data with 12-month administrative claims and updates data on a weekly basis to predict real-time risk of hospitalization for primary care patients. Similarly, Hu et al., (2015), developed a model to assess patient risk of ED visits and integrated this tool into an accessible, web-based dashboard used to inform care. Although prospective cohort studies explore prediction performance in real-time settings, Wallace et al., (2016) specifically note model characteristics which have advantages and lend to clinical utility, such as high-risk stratification. Lastly, the Devon Predictive Model identifies clinicians of patients within the top 5% highest risk of hospital admission to inform case management care.69
Inclusion and Use of Prediction Variables
Table 2 presents the 20 most common variables included in final models across all outcomes. Within the 31 studies, 51 various sets of predictive features were examined. Prediction features were classified into 9 broad categories: sociodemographic variables, patient health profile, medical history, medication use, clinical findings, procedure history, health service utilization, social supports, and others.
Top 20 Predictor Variables Included and Considered in Models Predicting Emergency Department Visits, Hospitalizations, and Mortality
Across all prediction outcomes, age (n = 45, 88%), specific medical diagnoses (n = 43, 84%), and sex (n = 40, 78%) were the top 3 variables most frequently included in final models. Twenty-nine (57%) models included medication use, a variable often captured by a count of individual prescriptions, medication classifications, or drug classes. Prior health service utilization, often examined within the past year, is a key variable commonly included in final prediction models. This included both prior hospital admissions and emergency department visits. Less frequently, the number of inpatient bed days was included as a final prediction variable. Across all outcomes, medication use was frequently included in final prediction models (ED visits, n = 4, 50%; hospitalizations, n = 13, 62%; mortality, n = 12, 75%). Clinical laboratory results, such as levels of bilirubin and creatinine, were included in 22 final models (43%), and several models considered and included sociodemographic variables such as race/ethnicity, socioeconomic status, access to care, marital status, and insurance payer.
Of the 31 included studies, 6 studies (19.4%) did not report the candidate predictor variables evaluated, and 7 studies (22.6%) did not report the relative predictive strength of individual variables. Of the studies which presented variable importance, notable overlap was found between variables frequently included in final models and those which held significant predictive value.
More specifically, age and specific medical diagnoses were identified as strong predictive contributors across all predictive outcomes, and less commonly, prior hospitalizations and laboratory results also demonstrated significant predictive power.
Two studies included free-text medical record data; 1 study used both structured and unstructured data fields for prediction,46 whereas another solely processed free-text data and fit models using individual and strings of text.63
Predictive Accuracy of Included Studies
For studies with more than 1 prediction model, those with the highest c-statistic were considered the preferred/selected model. Table 1 presents an overview of model development and performance for each predictive outcome. Overall, almost all studies (n = 30, 97%) reported discrimination using c-statistics, of which the selected models ranged from 0.57 to 0.95 after validation. Of the best-performing models, the average c-statistics for ED visits, hospitalizations, and mortality were 0.73, 0.77, and 0.81, respectively. Twenty-four (77%) studies presented at least 1 measure of sensitivity, specificity, positive predictive value, or negative predictive value, often at various levels of predicted risk or probability thresholds.
Methodological Quality of Included Studies
Overall, the methodological quality of the included studies was poor. Although most studies included sufficient information on participants, many did not provide sufficient details on their specific analyses (Table 3). Calibration assesses the alignment between the probabilities predicted by the model and the actual observed probabilities of outcomes. In a well-calibrated model, predicted probabilities match the true probabilities of events, indicating that the model's predictions are not systematically too high or too low. Less than half of the studies reported calibration; the most frequently used methods of assessing calibration were calibration curve (n = 7), Hosmer-Lemeshow test (n = 4), less frequently, reported slope or raw predicted and observed values. Of these, 12 studies reported that models were well calibrated or stated that results indicated good calibration.
Methodological Quality Assessment of Included Prediction Models following the Prediction Model Risk of Bias Assessment Tool (PROBAST) Guidelines
Discussion
The aims of this systematic review were threefold: 1) to examine candidate predictors which contribute to high-performing prediction models; 2) describe model performance; and 3) assess model suitability to contribute to clinical care and decision making. This systematic review included 31 studies with 36 unique prediction models which process primary care electronic medical record data. Sixteen (44.4%) of the models aimed to identify individuals at risk of hospitalization, 7 (19.4%) focused on the risk of ED visits, and 13 (36.1%) on the risk of mortality. Although a number of studies focused on specific populations such as patients with chronic kidney disease or HIV-positive patients admitted to hospital, most risk prediction models were developed in an adult general practice or community hospital population. Of the best-performing models within each study, more than 85% of models demonstrated adequate or good prediction accuracy. Across all prediction outcomes, models which showed poor predictive accuracy were often developed and validated using smaller sample sizes.
This review identified numerous variables widely found to be important predictors of emergency department visits, hospitalizations, and mortality, including age, prior health care utilization, medical diagnoses, and sex. In contrast to the current study, functional status, and activities of daily living,70 as well as measures of multimorbidity and disease severity,71 were common and significant predictors identified in other reviews of prediction models. This finding is noteworthy given the research which highlights the association between these variables and the outcomes of interest. For example, disease severity was found to have a significant association with emergency department use,72 and the development of the well-known LACE index found Charlson Comorbidity score to be 1 of 4 variables independently associated with mortality or 30-day hospital readmission.73 This could point toward a paucity of such patient information routinely collected and/or systematically stored within primary care EMR data.
Further, a growing amount of literature has supported the feasibility and benefits of processing EMR free-text and clinical notes for predictive modeling.74 However, despite the amount of rich medical record data available in unstructured fields, only 2 studies46,63 included in the current review utilized free-text data for prediction.75,76 The absence of unstructured EMR data in prediction models may indicate a missed opportunity to process all available data in an effort to expand and improve predictive models within PHC.
Consistent with previous research,77,8 more than half of the studies included at least 1 measure of patient sociodemographic data in final prediction models, including those which demonstrated high predictive performance. As primary care EMR data facilitates the use of routinely collected patient information valuable for prediction, this finding may reflect the increasing recognition of sociodemographic variables, such as socioeconomic status, as important patient data to be systematically collected across health systems.78
Previous research has explored the prediction of emergency department visits, hospitalization, or mortality, which process broad sources of data, including administrative, and self-report and survey data in addition to EMR data. Overall, the distribution of predictive ability reported in previous literature is consistent with that found across outcomes in the current review. A number of reviews have focused on the prediction of hospitalization and have reported c-statistics ranging from 0.60 to 0.83.,71 Furthermore, 2 reviews exploring the accuracy of mortality prediction tools reported similar discriminative ability, with c-statistics ranging from 0.56 to 0.85.79 Although a portion of these models demonstrate adequate predictive accuracy, research highlights the importance of harnessing and building on robust model development and evaluation features, particularly due to the clinical implications of deficits in model performance.80
Many of the studies included in this review demonstrated poor reporting of predictive methodology and analyses. This is a common critique across multiple systematic reviews, which have also emphasized the need for improved reporting, external validation, and approaches to mitigate bias and the appropriate handling of missing data.79,81 Thorough reporting of methods and results is particularly important for reproducibility, given the increasing amount of new models emerging in the field and the increasing potential for uptake of these models in clinical practice. Future research should adhere to the Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD)82 statement to report the development and validation of predictive models. Only 4 studies discussed or considered clinical implementation in the study/model design. This is particularly important as there are many barriers to translation from a model on article to an effective predictive tool in clinical practice.
Strengths and Limitations
There are several strengths of the current review. There is a lack of systematic reviews which examine the use of primary care electronic medical record data in the prediction of emergency department visits, hospitalizations, and mortality. This review helped address critical gaps in the literature regarding the potential of primary care EMR data. Further, by bringing together a number of important prediction outcomes, this review provided connections between outcomes, and a comparison of insights. In addition, the use of a comprehensive search strategy has contributed to a robust, and extensive review spanning multiple countries and populations. However, there are limitations. First, the exclusion of models that predict multiple endpoint outcomes, such as models which predict hospitalization or mortality, may inadvertently overlook valuable insights that could enrich the existing literature. Second, the current search included only English studies, which may limit the scope of the available evidence. Lastly, although the findings in this review provide a comprehensive overview of the available research, inconsistent reporting of prediction model development and analysis may limit the ability to draw conclusions from findings presented here.
Conclusion
This review identified 31 studies which apply prediction methods to primary health care electronic medical record data to predict unplanned ED visits, hospital admissions, and mortality. Although demonstrating variable predictive performance, many models share commonalities in predictive variables of importance. Future research can build on these findings to develop and evaluate algorithms used to predict health service use, using EMR primary care EMR data. Such algorithms could be integrated into the workflow of primary care clinicians and clinics. For example, teams could set aside time at the beginning of the week to review a list of patients identified at high-risk, and identify actions (ie, outreach, booking a visit, organizing tests). Over time, such a system could be trained on data on the action taken (or lack of action) and perform better over time. Despite more work required to improve the quality and reporting of such models, the use of primary care EMR data for use in predictive analytics holds promise.
Acknowledgments
We are grateful to Melissa Perri, Rachelle Perron and Aakriti Pyakurel for assistance with reviewing the literature, and Robert Smith for input on this study. We appreciate helpful comments from Tyler Williamson and Jeremy Petch.
Appendix A
Sample Search Strategy



Appendix B
Systematic Review Data Extraction Fields, Guided by the CHARMS Checklist


Notes
This article was externally peer reviewed.
Funding: This project was supported in part by an Early Researcher Award from the Government of Ontario. Andrew Pinto is supported as a Clinician-Scientist by the Department of Family and Community Medicine, Faculty of Medicine at the University of Toronto and St. Michael’s Hospital, and the Li Ka Shing Knowledge Institute, Unity Health Toronto. He is also supported by a CIHR Applied Public Health Chair. The opinions, results and conclusions reported in this article are those of the authors and are independent of any funding sources.
Conflict of interest: The authors have no conflicts of interest to declare.
To see this article online, please go to: http://jabfm.org/content/37/4/583.full.
- Received for publication October 20, 2023.
- Revision received February 11, 2024.
- Accepted for publication February 12, 2024.
References
- 1.↵
- 2.↵
- 3.↵
- 4.↵
- 5.↵
- 6.↵
- 7.↵
- 8.↵
- 9.↵
- 10.↵
- 11.↵
- 12.↵
- 13.↵
- 14.↵
- 15.↵
- 16.↵
- 17.↵
- 18.↵
- 19.↵
- 20.↵
- 21.↵
- 22.↵
- 23.↵
- 24.↵
- 25.↵
- 26.↵
- 27.↵
- 28.↵
- 29.↵
- 30.↵
- 31.↵
- 32.↵
- 33.↵
- 34.↵
- 35.↵
- 36.↵
- 37.↵
- 38.↵
- 39.↵
- 40.↵
- 41.↵
- 42.↵
- 43.↵
- 44.↵
- 45.↵
- 46.↵
- 47.↵
- 48.↵
- 49.↵
- 50.↵
- 51.↵
- 52.↵
- 53.↵
- 54.↵
- 55.↵
- 56.↵
- 57.↵
- 58.↵
- 59.↵
- 60.↵
- 61.↵
- 62.↵
- 63.↵
- 64.↵
- 65.↵
- 66.↵
- 67.↵
- 68.↵
- 69.↵
- 70.↵
- 71.↵
- 72.↵
- 73.↵
- 74.↵
- 75.↵
- 76.↵
- 77.↵
- 78.↵
- 79.↵
- 80.↵
- 81.↵
- 82.↵
- 83.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}