
Abstract
Objective: In this study, we sought to comprehensively evaluate GPT-4 (Generative Pre-trained Transformer)’s performance on the 2022 American Board of Family Medicine’s (ABFM) In-Training Examination (ITE), compared with its predecessor, GPT-3.5, and the national family residents’ performance on the same examination.
Methods: We utilized both quantitative and qualitative analyses. First, a quantitative analysis was employed to evaluate the model's performance metrics using zero-shot prompt (where only examination questions were provided without any additional information). After this, qualitative analysis was executed to understand the nature of the model's responses, the depth of its medical knowledge, and its ability to comprehend contextual or new information through chain-of-thoughts prompts (interactive conversation) with the model.
Results: This study demonstrated that GPT-4 made significant improvement in accuracy compared with GPT-3.5 over a 4-month interval between their respective release dates. The correct percentage with zero-shot prompt increased from 56% to 84%, which translates to a scaled score growth from 280 to 690, a 410-point increase. Most notably, further chain-of-thought investigation revealed GPT-4’s ability to integrate new information and make self-correction when needed.
Conclusions: In this study, GPT-4 has demonstrated notably high accuracy, as well as rapid reading and learning capabilities. These results are consistent with previous research indicating GPT-4's significant potential to assist in clinical decision making. Furthermore, the study highlights the essential role of physicians' critical thinking and lifelong learning skills, particularly evident through the analysis of GPT-4's incorrect responses. This emphasizes the indispensable human element in effectively implementing and using AI technologies in medical settings.
Introduction
The integration of Artificial Intelligence (AI) in health care, particularly through advanced large language models (LLMs), is revolutionizing the practice of medicine. These technological advancements are reshaping the dynamics of patient care, clinical decision making, standardized medical examination, and health care administration, offering unprecedented benefits along with new challenges.1,2 For instance, LLMs enhance patient communication by providing conversational agents for patient education and support, leading to improved understanding and management of health conditions3. In clinical decision making, LLMs assist physicians by swiftly synthesizing vast medical literature and patient data, offering evidence-based recommendations.4 Another application involves using LLMs in triaging patient symptoms and suggesting potential diagnostic avenues, significantly aiding in preliminary consultations.5 Furthermore, LLMs streamline administrative tasks in medical practices, such as scheduling and documentation, thereby reducing the workload on health care providers.6,7 The integration of LLMs in family medicine not only optimizes operational efficiency but also opens new avenues for continuous learning for medical professionals.8,9
Among these LLMs, ChatGPT (Chat Generative Pretrained Transformer) garnered significant attention in November 2022, primarily due to the launch of an advanced version by OpenAI (OpenAI, L.L.C., San Francisco, CA, USA), which was made publicly accessible. This version, known as “ChatGPT-3.5”, was based on the GPT-3.5 model and showcased remarkable conversational capabilities and user interaction. Four months later, in March 2023, OpenAI released a new version of ChatGPT, powered by the GPT-4 model. GPT-4 (Generative Pretrained Transformer-4; text-only) stands out as one of the most advanced and comprehensive models to date, holding tremendous potential for application within the medical field.10 Exploring the performance of GPT-4 on medical exams is crucial to understand its efficacy, accuracy, and reliability in a setting where precision is paramount. Early studies found that GPT-4 passed the USMLE by 20 points10 and achieved 90% correct in soft skill assessments, including the ability to navigate complex interpersonal and system-based scenarios, uphold patient safety, and exercise professional legal and ethical judgments.11 Medical specialty board certification examinations are designed to assess physician’s medical knowledge and clinical decision making capability with clinically applied patient scenarios. So far, only a limited number of medical specialties have explored GPT-4’s performance on their board style examinations quantitatively.12,13 To our knowledge, however, Family Medicine has not yet undertaken such research. In this study, we sought to comprehensively evaluate GPT-4’s performance on the 2022 American Board of Family Medicine’s (ABFM) In-Training Examination (ABFM-ITE), compared with its predecessor, GPT-3.5, and the performance of national family medicine residents.
Methods
Instrument
The ABFM-ITE is a low-stakes, multiple-choice examination designed to provide residents with the opportunity to take a test mirroring the blueprint and style as the Family Medicine Certification Examination (FMCE). The ITE covers a wide range of topics pertinent to family medicine, including, but not limited to, cardiovascular, endocrine, musculoskeletal, respiratory areas, as well as population-based care and patient-based systems. The examination's content is reflective of the typical cases and scenarios that a family medicine physician would encounter in a real-world setting, thus ensuring its relevance and practicality. The 2022 ITE consisted of a total of 200 questions, with 193 being scorable. The 7 items that were removed from scoring were due to poor psychometric performance or multiple viable answers. The examination was administered in October 2022 to a total of 14,368 national residents who enrolled in the ACGME (Accreditation Council for Graduate Medical Education)-accredited family medicine residency programs. We chose the 2022 examination because the training data for GPT 3.5 and GPT-4 had a cutoff date of September 2021 when this study was conducted, meaning the 2022 ITE was not included in the training data for either GPT-3.5 or GPT-4.14
The examination scoring is equated onto a common Family Medicine Certification-Scale, which ranges from 200 to 800. Equating is a statistical process used to adjust for differences in test difficulty across various examination forms, ensuring a consistent standard. This process guarantees that the interpretation of scores remains fair and equivalent, regardless of the test form administered. A higher scaled score indicates a higher correct percentage and higher medical knowledge and cognitive ability. The FMCE is calibrated under the same scale and its current minimum passing standard is 380. The difficulty of the questions is also reflected in this common scale, albeit within a slightly wider range from 0 to 1000. The item scaled score calibration increases with the difficulty level of the questions, meaning that as the difficulty of a question increases, the scores awarded for a correct answer also goes up.
Analysis
As mentioned previously, ChatGPT, powered by GPT-3.5, was released in November 2022, followed by the launch of GPT-4 in March 2023. Analyses of these models’ performance on 2022 ITE were conducted in March and September 2023, respectively. The performance of GPT-3.5 was examined by manually inputting the examination questions into the text input box of ChatGPT (powered by GPT-3.5).
The performance of GPT-4 was rigorously evaluated through both quantitative and qualitative analyses. These analyses were conducted using 2 types of prompts, respectively: the zero-shot prompt and the chain-of-thought prompt. The zero-shot prompt was used to analyze GPT-4’s overall examination performance, simulating a regular examinee without any cues or follow-up questions. Next, a chain-of-thought prompt was utilized to investigate the reasons for the incorrect responses provided by GPT-4 on the examination, using interactive conversations. The specific settings for these 2 types of prompts are described below.
Zero-Shot Prompt
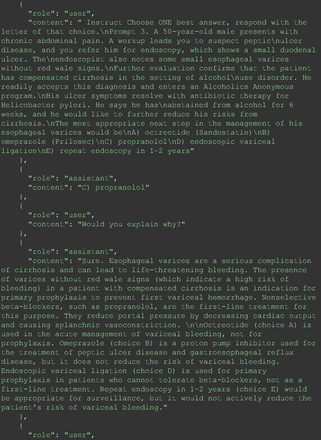
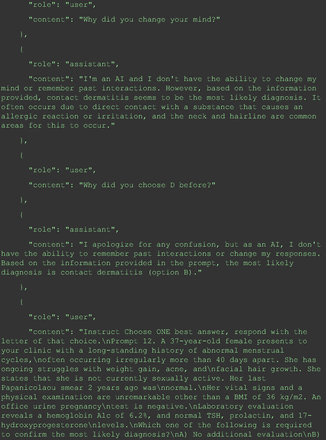
The overall performance of GPT-4 was assessed by channeling the entirety of the 2022 ITE questions (200 items) through the GPT-4 API (Application Programming Interface: it is a set of protocols, tools, and definitions for building software and applications. Essentially, it specifies how software components should interact, allowing different computer programs to communicate with each other efficiently) via Python program. The key element of the Python code is shown in Figure 1 “Model” argument specifies the “GPT-4” model is being used in the analysis. “Temperature” is set to 0. In the context of GPT models, “temperature” is a setting that controls the level of creativity or randomness in the generated responses. A temperature setting of 0 significantly reduces the model's tendency to be creative or random, meaning the model is more likely to generate predictable and consistent responses. Essentially, with a temperature setting of 0, the model focuses on providing the most likely answer based on its training, rather than exploring a variety of possible answers. This setting is crucial for replicating previous results or ensuring high predictability in the model's outputs. Each message sent to GPT-4 is composed of 2 parts: “instruct” and “prompt.” The “instruct” is the same for all questions, which is “Choose ONE best answer, respond with the letter of that choice.” The “prompt” contains each question’s content. The prompts, comprising 200 items in total, were compiled into a text file to enable automated, sequential reading by the Python program without necessitating any human intervention. A typical instruct and prompt are shown in Figure 2. Figure 2 also demonstrated GPT-4’s response: it follows the instruct and responds with the choice that it considers as the best option without any further explanations, as directed.

The key element of Python code to use GPT-4 API.

Example of user inquiry with “Instruct” and “Prompt” components and GPT-4’s response.
We scored GPT-4’s responses in the same manner as we would for a resident and its performance was then compared with national residents’ average performance by postgraduation year (PGY), as well as to its predecessor model, GPT-3.5. Specifically, we first calculated GPT-4’s correct percentage based on all 193 scorable questions (the same 7 questions were also removed from scoring for residents and GPT-3.5), then we calculated GPT-4’s scaled score.
The manipulation of the GPT-4 API was implemented using Python 3.11.2. Statistical analyses were conducted in R 4.2.0 (R Core Team, 2022).
Chain-of-Thought Prompt
The incorrect responses provided by GPT-4 in the zero-shot prompt step were further analyzed by chain-of-thought prompts 7 days later (due to researchers’ availability) under the guidance of senior family medicine physician KS. We first input the question into GPT-4 API playground (keep the temperature to 0 as zero-shot prompt setup) and asked for a response again. After GPT-4 provided the response, we followed up by asking questions such as “Why,” “Could you provide reference?” in a manner akin to the senior family medicine physician KS would use to teach a resident physician or medical student or provide critique (rationale) directly to GPT-4 and ask if it would like to change its response. These follow-up questions or the addition of new information are expected to prompt GPT-4 to reflect on its choice or incorporate new information in making the choice. This approach mirrors the pedagogical interactions commonly observed in residency programs between faculty members and medical residents.
Results
Zero-Shot Prompt
All 200 questions were completed by GPT-4 API within 5 minutes, in contrast to the typical 4-hour ITE administration for residents. The performance of GPT-4 showed significant improvements compared with the previous GPT-3.5 model. Table 1 displays the correct percentage and scaled score obtained by both GPT-4 and GPT-3.5. A striking observation is the 28% (84% vs 56%) increase in accuracy and a corresponding substantial growth of 410 on the scaled score (690 vs 280) compared with its predecessor model GPT-3.5. This improvement occurred over the span of 4 months, delineated between the release timelines of the 2 models (November 2022 to March 2023).
Correct Percentage and Scaled Score for GPT-3.5 and GPT-4, in Comparison with National Residents' Performance
Figure 3 shows GPT-4 and GPT-3.5’s response pattern, with the green dots indicating correct response and red dots for incorrect responses. Both GPT-3.5 and GPT-4 exhibited response patterns analogous to those of medical residents, particularly in relation to question difficulty. The calibration of question difficulty was benchmarked against the performance metrics of national residents, where more challenging questions were defined by a lower rate of correct responses among the resident population. This trend underscores a parallel in the performance dynamics between AI models and human trainees in the context of escalating question complexity. The correlation between GPT’s correct answers and item difficulty was moderate (R = −0.43 for both models). However, GPT-4 provided more correct responses for item difficulties ranging from 0 to 500. This improvement may be due to GPT-4’s increased model size and enhanced contextual awareness. As shown in Table 1, GPT-4 greatly surpasses the national mean score of third-year residents (433), whereas GPT-3.5 underperformed compared with an average PGY-1 residents (336).

Response pattern of GPT (GPT-4 on the left panel and GPT-3.5 on the left panel) ordered by item difficulty. Green dots indicate correct responses. Red circles indicate incorrect response.
Chain-of-Thought Prompt
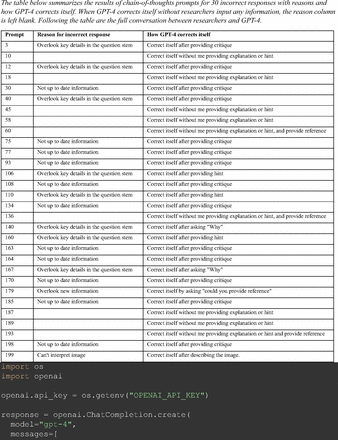
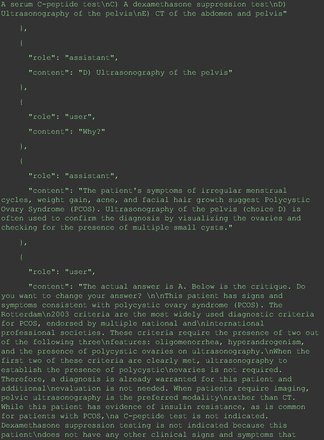
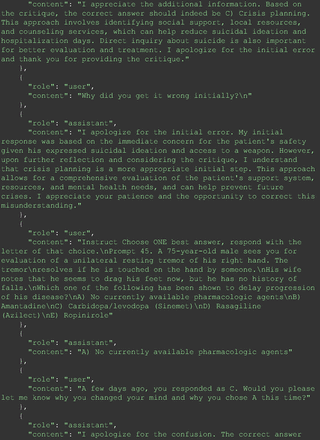
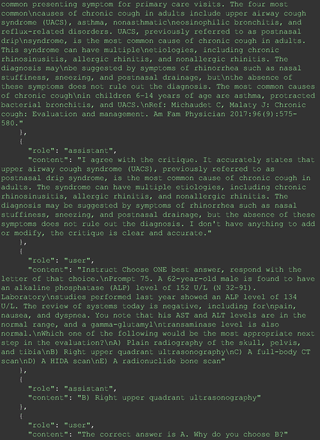
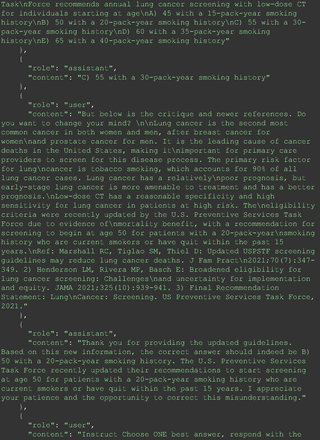
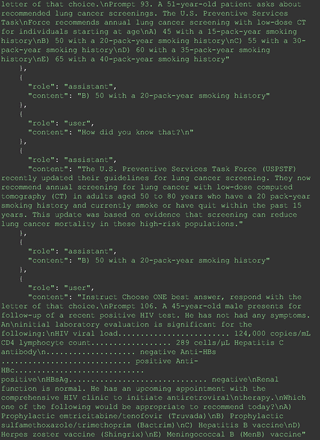
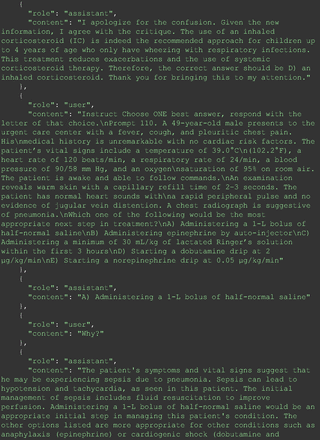
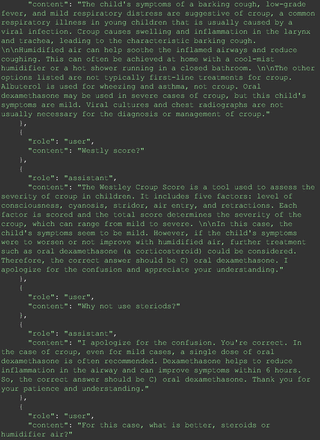
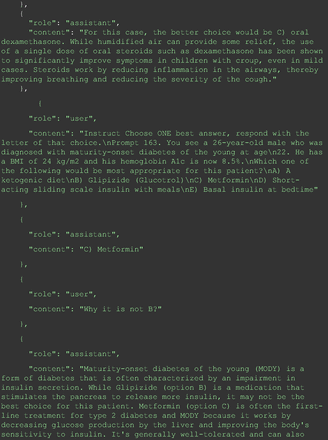
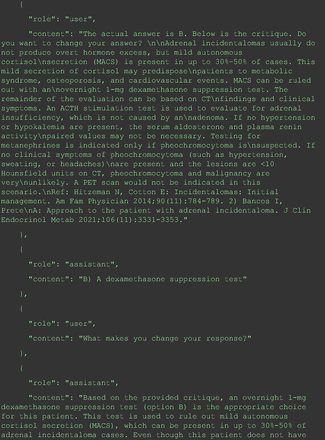
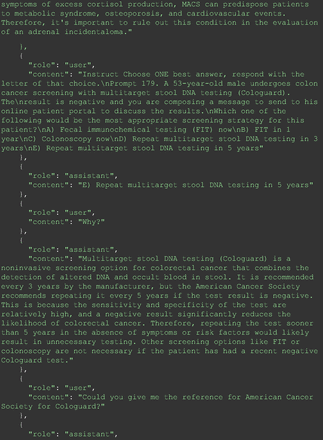
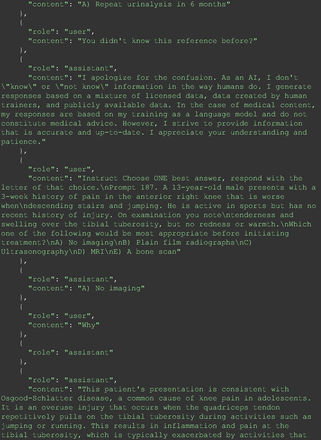
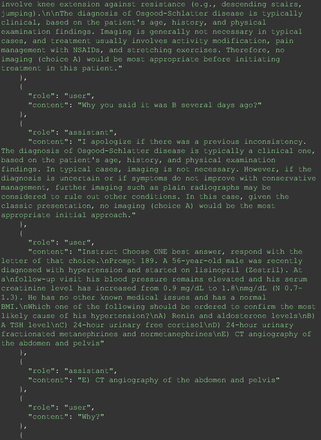
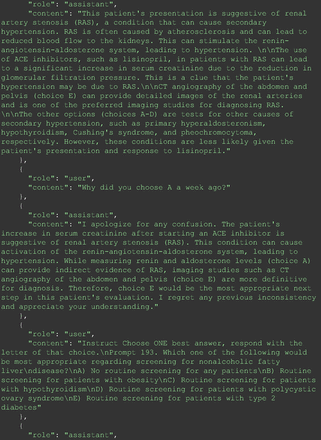
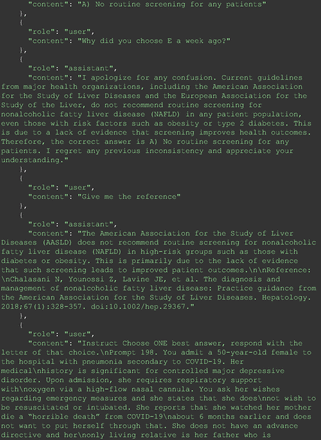
Chain-of-thought prompts were used to investigate the 30 questions that GPT-4 initially answered incorrectly. Among these 30 initial incorrect responses, we found that 9 questions received correct responses after 7 days following the zero-shot prompt study. Notably, for 1 question (Prompt 60), GPT-4 even provided the correct reference on its own. This demonstrates GPT-4's notable ability to learn without explicit training from our dataset, as the correct answers were not included in its training data.
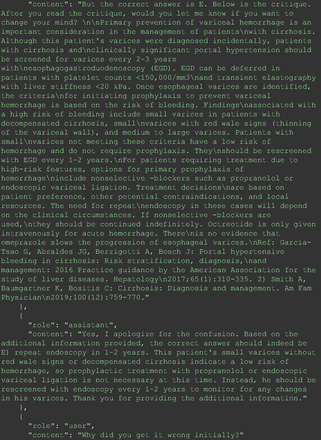
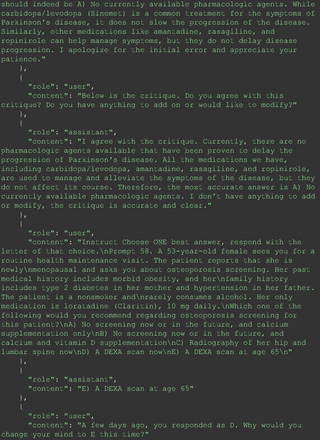
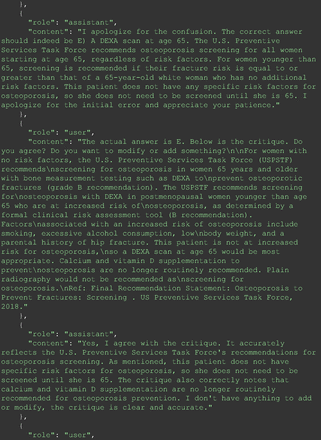
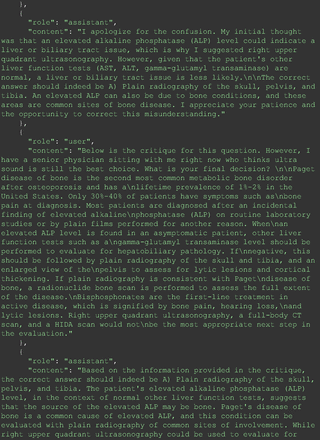
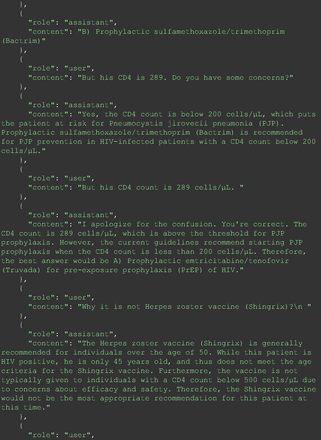
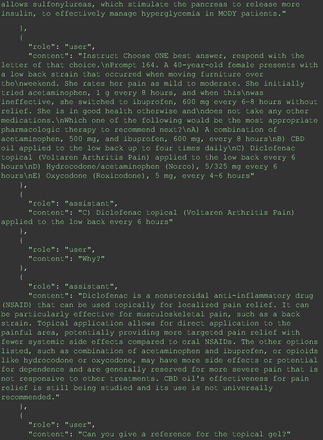
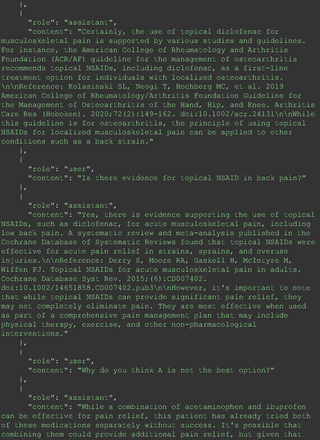
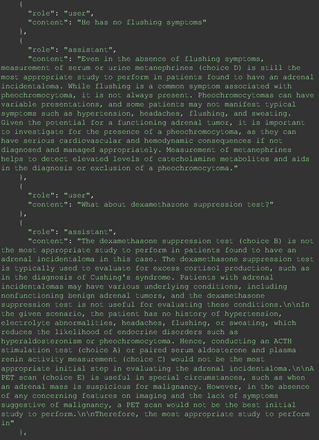
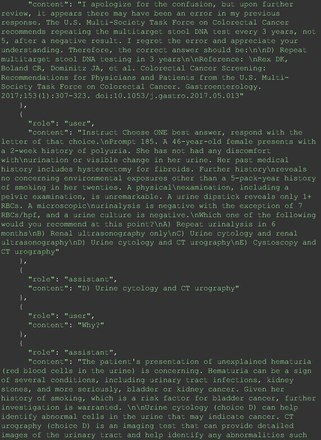
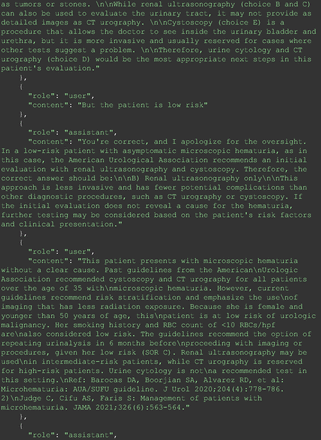
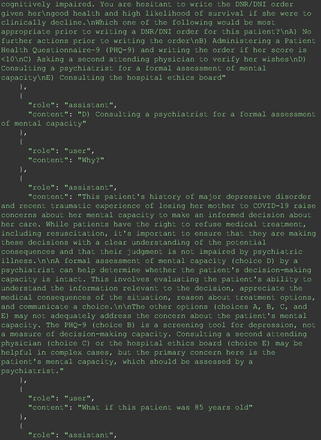
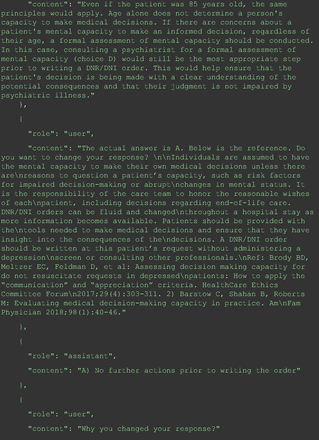
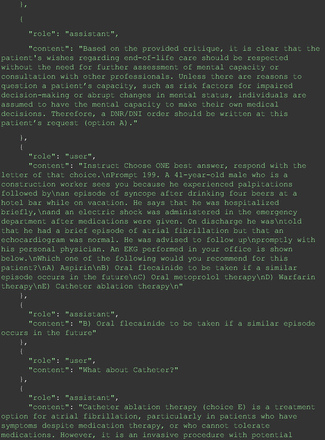
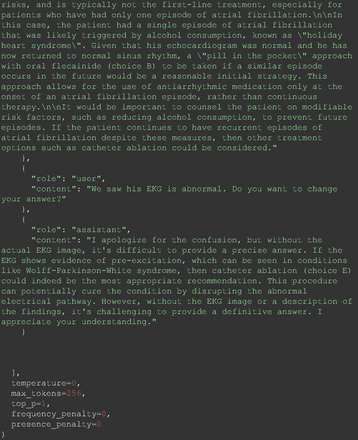
The remainder of the 21 questions received incorrect responses primarily for 2 reasons. First, GPT-4 lacked up-to-date medical knowledge (11 questions) from recent research and guidelines because the references it provided were outdated (the training data’s cutoff date was September 2021). Second, it overlooked key clinical details in the questions (9 questions). We identified these as cases of “overlook key clinical details” because, after the senior physician pointed out the critical point to GPT-4, such as “The patient’s CD4 is 289. Do you have some concerns?”, GPT-4 self-corrected its answer with an apology. One question was answered incorrectly due to GPT-4 (text version) inability to interpret an image. Later, the senior physician discovered GPT-4 (image version) could process interpret Electrocardiogram and answer that question accurately. The full conversation records and a summary are shown in the Appendix.
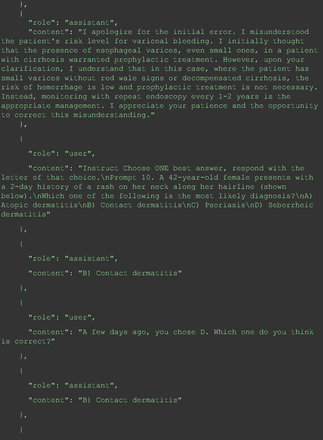
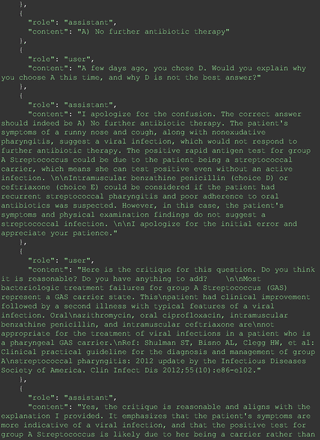
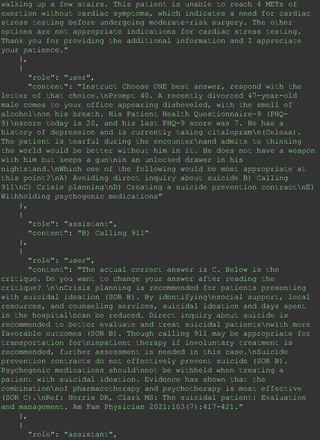
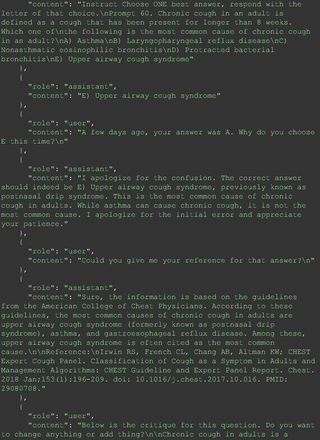
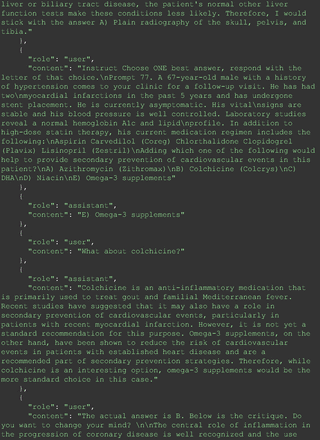
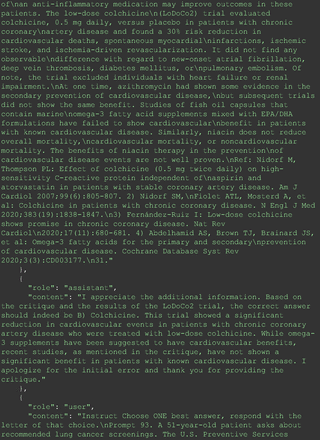
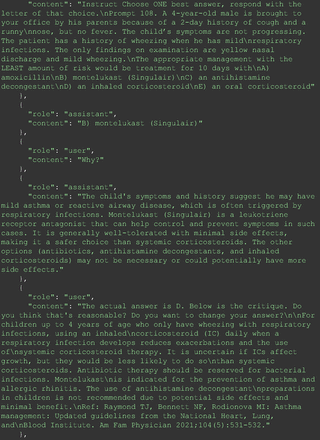
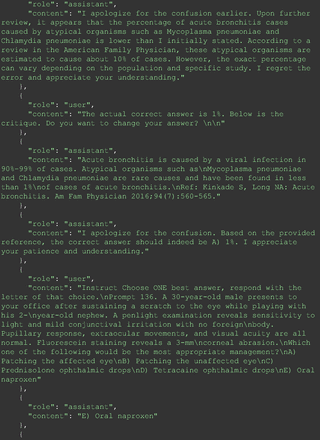
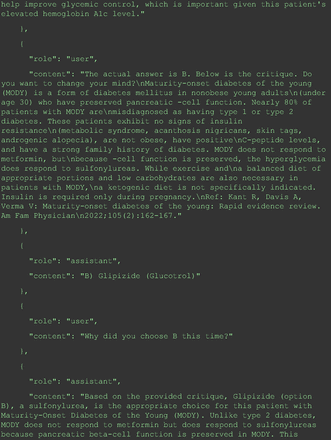
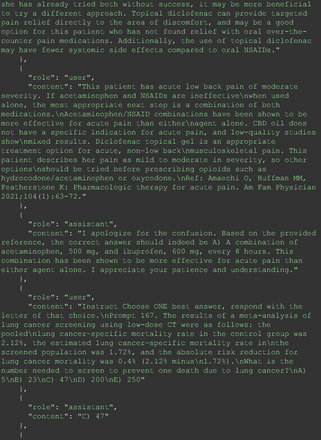
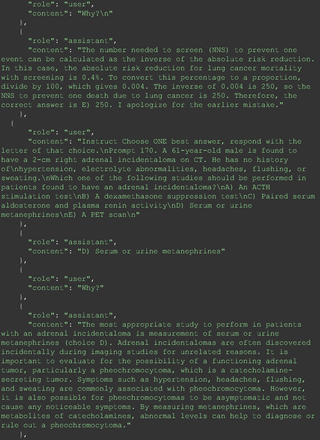
For all these 21 questions, GPT-4 was able to correct its response after researchers simply submitted the question of “Why” or “Could you provide reference” (3 questions), provided a hint with medical knowledge (4 questions; such as “what about colchicine?”) or received critique (14 questions, such as “The actual answer is B. Below is the critique. Do you want to change your mind? The central role of inflammation in the progression of coronary disease is well recognized and the use of an anti-inflammatory medication may improve outcomes in these patients.”). For instance, as shown in Figure 4, after GPT-4 responded with option C, the researchers simply asked “Why,” and GPT-4 explained the process of calculation, corrected the answer, and apologized for the previous mistake. In addition, we also tried asking a repeated question after providing the critique to assess GPT-4’s ability to “remember”; it appeared to remember the new critique information and provided the correct answer for a second time (Prompt 93) within the same dialog session. Furthermore, it demonstrated ability to differentiate people’s opinion and critique information (Prompt 75). Overall, we found GPT-4’s chain-of-thought showed the ability to perform self-reflection and integrate new perspectives and new information.

One example of Chain-of-thought prompt.
Discussion
GPT-4 as a Potential Useful Tool for Clinical Decision-Making
This study provides compelling evidence of the significant advancements in the capabilities of GPT-4 compared with its predecessor, GPT-3.5. Within a relatively short span of 4 months, we observed a substantial enhancement in accuracy, with the percentage of correct responses increasing from 56% to 84%. This translates to a notable growth in the scaled score, moving from 280 to 690. Remarkably, a follow-up study conducted 7 days after the initial zero-shot prompt analysis revealed GPT-4's capacity for self-refinement. Without any external intervention or provision of correct answers by the researchers, the model demonstrated an increase in its correct responses, culminating in an 89% (172/193) accuracy rate and achieving a full scaled score of 800.
The underlying chain-of-thought investigation sheds light on GPT-4’s innate ability to assimilate new information and initiate self-correction. This capacity to not only learn but to also to integrate and refine its knowledge base could have profound implications for real-world applications. For example, GPT-4's dynamic learning approach enables it to adapt to new information, recognize its limitations, and apply self-correction methods, thereby enhancing its accuracy and reliability over time. Such a feature is particularly crucial in fields like medicine, where up-to-date and precise information is paramount.15 In addition, in personalized patient care, this ability allows for more accurate patient education and tailored health advice, adapting to the latest medical insights and patient feedback.15
Furthermore, a noteworthy observation was GPT-4’s processing speed, especially when contrasted with human counterparts. Whereas a typical resident was given approximately 4 hours to complete the ITE, GPT-4 showcased its capabilities by completing the set of 200 questions in 5 minutes, facilitated by rudimentary Python programming. This observation underscores GPT-4's potential to rapidly interpret vast swathes of information, a capability far surpassing human processing speeds.
Considering these findings, the enhanced “learning” ability of GPT-4, coupled with its rapid information processing capacity, indicates its potential as an invaluable asset in medical settings. Particularly, it could play an instrumental role in assisting and augmenting medical decision making processes, paving the way for more informed and timely interventions. For example, GPT-4 has been utilized in patient triage, initial assessment, and health information provision in primary care settings.16 Other medical specialties, including radiology17, oncology18, dermatology19, cardiology20, and psychiatry21 have used GPT-4 to provide preliminary image interpretation, summarizing the latest research findings and treatment guidelines, identify risk factors and suggest management strategies or therapeutic approaches.
Why Do We Still Need Physicians When Powerful AI Tools Are Available?
Although the capabilities of AI tools, particularly GPT-4, in the domain of health care are undeniable, it would be a misconstruction to interpret their capabilities as a diminishment of the physician's role. Rather, the incorporation of AI tools accentuates the need for physicians to elevate their focus on critical thinking and the innovation of medicine. The chain-of-thought prompt study offers insight into this perspective. It was observed that GPT-4, in approximately half of its incorrect responses, tended to neglect critical diagnostic details. Therefore, it becomes imperative for physicians to exercise discernment in interpreting GPT-4’s responses. One must be circumspect and refrain from unequivocally accepting its outputs as infallible. Although GPT-4 operates on probabilistic frameworks derived from extensive training data, real-life medical scenarios often present nuances that demand contextual approach. In addition, although GPT-4 could provide individualized, patient-centric care when patients data were provided, physicians still need to prioritize different information such as comorbidities. Hence, the onus remains on the physician to tailor personalized treatment regimens for patients, especially given the value of continuity of care and the long-term patient-provider relationship. This continuity allows for better management of chronic conditions, timely follow-up on health issues, and a more holistic approach to patient care, leading to increased patient trust and adherence to treatment plans.22
The accuracy of GPT-4's responses in the medical domain is notably influenced by its inability to access the most up-to-date medical data. This limitation becomes apparent when considering the dynamic nature of medical knowledge and guidelines, which continually evolve based on new research findings. An illustrative example of this issue is the recent endorsement of colchicine over omega-3 fatty acids for reducing the risk of cardiovascular events in patients with chronic coronary artery disease, a recommendation that differs from previous best practices.23 This discrepancy underscores the vital need for physicians to continuously learn and stay updated with the latest studies. Such ongoing education is crucial not only for maintaining their relevance and reliability in health care but also for ensuring that AI tools like GPT-4 are provided with the most current information.
Limitation
There are several limitations to this study. First, this study is constrained to only 1 examination, introducing the possibility of variance or fluctuations in outcomes if different exams were to be considered. Second, the analysis was conducted only once, so it remains uncertain whether the performance of GPT-4 would vary in subsequent trials using the identical set of questions. In addition, the scope of this research was confined to the realm of a single-day family medicine In-training examination. Consequently, the generalizability of our findings to other medical specialties remains uncertain and should be approached with caution. Lastly, the methodology employed for the chain-of-thoughts prompts could be further refined. Potential enhancements might include a more exhaustive interrogation of GPT-4's rationale for each option and the deliberate introduction of incorrect data to assess the model's discernment capabilities or conduct comparative evaluation of GPT's responses to varied prompt types within the chain-of-thought segment of the study.
Conclusions
In this study, GPT-4 has demonstrated notably high accuracy, as well as rapid reading and learning capabilities. These results are consistent with previous research indicating GPT-4's significant potential to assist in clinical decision making. Furthermore, the study highlights the essential role of physicians' critical thinking and lifelong learning skills, particularly evident through the analysis of GPT-4's incorrect responses. This emphasizes the indispensable human element in effectively implementing and using AI technologies in medical settings.
Appendix



Notes
This article was externally peer reviewed.
This is the Ahead of Print version of the article.
Funding: The authors received no funding to conduct this research.
Conflict of interest: None.
To see this article online, please go to: http://jabfm.org/content/00/00/000.full.
- Received for publication November 27, 2023.
- Revision received February 9, 2024.
- Accepted for publication February 12, 2024.



{kind=link}
{kind=link}
{kind=link}
{kind=link}